7.3. Pgpool-II + Watchdogの構築の例
ここでは、ストリーミングレプリケーション構成のPostgreSQLをPgpool-IIで管理するシステムの構成例を示します。この例では、3台のPgpool-IIを使ってPostgreSQLを管理し、単一障害点やスプリットブレインの起きない堅牢なクラスタを運用することが可能です。
7.3.1. 前提条件
Pgpool-IIサーバとPostgreSQLサーバが同じサブネットにあることを前提とします。
7.3.2. 全体構成
今回は、Linuxサーバを3台用意し、それぞれのホスト名は 「server1」、「server2」、「server3」 とします。使用するOSはすべてCentOS 7.4とします。それぞれのサーバにPostgreSQLとPgpool-IIをインストールします。3台のPostgreSQLがストリーミングレプリケーション構成になります。全体構成図は以下の通りです。
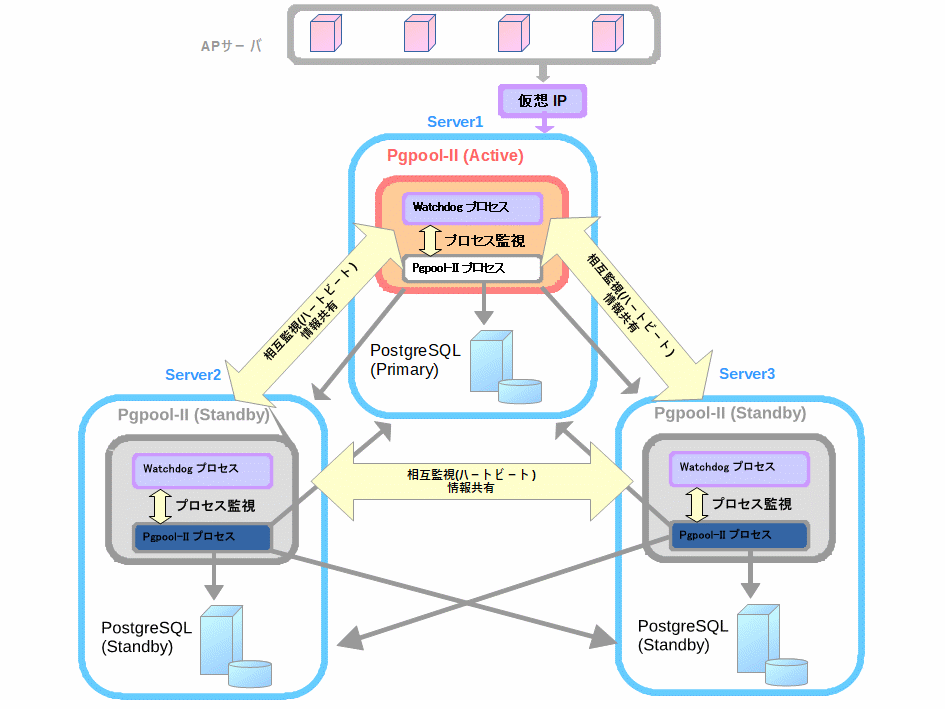
注意: 「アクティブ」「スタンバイ」「Primary」「Standby」といった役割は固定されているものではなく、運用と共に変化することがあります。
表 7-2. ホスト名とIPアドレス
| ホスト名 | IPアドバイス | 仮想IP |
|---|---|---|
| server1 | 192.168.137.101 | 192.168.137.150 |
| server2 | 192.168.137.102 | |
| server3 | 192.168.137.103 |
表 7-3. PostgreSQLのバージョンと設定情報
| 項目 | 値 | 説明 |
|---|---|---|
| PostgreSQLバージョン | 11.1 | - |
| ポート番号 | 5432 | - |
| $PGDATA | /var/lib/pgsql/11/data | - |
| アーカイブモード | 有効 | /var/lib/pgsql/archivedir |
| 自動起動 | 自動起動しない | - |
表 7-4. Pgpool-IIのバージョンと設定情報
| 項目 | 値 | 説明 |
|---|---|---|
| Pgpool-IIバージョン | 4.0.2 | - |
| ポート番号 | 9999 | Pgpool-IIが接続を受け付けるポート番号 |
| 9898 | PCPプロセスが接続を受け付けるポート番号 | |
| 9000 | watchdogが接続を受け付けるポート番号 | |
| 9694 | Watchdogのハートビート信号を受信するUDPポート番号 | |
| 設定ファイル | /etc/pgpool-II/pgpool.conf | Pgpool-IIの設定ファイル |
| Pgpool-II起動ユーザ | root | 通常のユーザでPgpool-IIを起動する場合の設定方法は項2.1.7をご参照ください。 |
| Pgpool-II動作モード | ストリーミングレプリケーションモード | - |
| Watchdog機能 | 有効 | ハードビート方式 |
| 自動起動 | 自動起動しない | - |
7.3.3. インストール
すべてのサーバにPostgreSQL 11.1とPgpool-II 4.0.2をRPMからインストールします。
PostgreSQLのインストールはPostgreSQLコミュニティのリポジトリを使います。
# yum install https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-7-x86_64/pgdg-centos11-11-2.noarch.rpm
# yum install postgresql11 postgresql11-libs postgresql11-devel postgresql11-server
Pgpool-IIのインストールはPgpool-II開発コミュニティが提供するYumリポジトリを用いてインストールします。
# yum install http://www.pgpool.net/yum/rpms/4.0/redhat/rhel-7-x86_64/pgpool-II-release-4.0-1.noarch.rpm
# yum install pgpool-II-pg11-*
7.3.4. 事前設定
PostgreSQLプライマリサーバのみでストリーミングレプリケーションの設定を行います。設定方法についてはここでは省略します。 スタンバイサーバの設定は、プライマリが起動した状態で、Pgpool-IIのオンラインリカバリ機能を使って行います。
この設定の例ではアーカイブリカバリを行うように設定します。
まず、すべてのサーバにてWALを格納するディレクトリ/var/lib/pgsql/archivedirを事前に作成します。
[全サーバ]# su - postgres [全サーバ]$ mkdir /var/lib/pgsql/archivedir次にserver1にて、設定ファイル$PGDATA/postgresql.confを以下のように編集します。
listen_addresses = '*' archive_mode = on archive_command = 'cp "%p" "/var/lib/pgsql/archivedir/%f"'Pgpool-IIのヘルスチェック及びレプリケーションの遅延チェックでPostgreSQLのユーザを設定する必要があります。セキュリティ上の理由で、この設定例ではスーパーユーザを使わないようにします。 Pgpool-IIのレプリケーションの遅延チェックとヘルスチェック用のユーザpgpoolを作成します。 また、PostgreSQLプライマリサーバserver1でレプリケーション専用ユーザreplを作成します。 Pgpool-II4.0からSCRAM認証を利用できるようになりました。この設定例では、scram-sha-256認証方式を利用します。 まず、password_encryption = 'scram-sha-256'に変更してから、ユーザを登録します。
表 7-5. ユーザ
ユーザ名 パスワード 備考 repl repl PostgreSQLのレプリケーション専用ユーザ pgpool pgpool Pgpool-IIのレプリケーション遅延チェック、ヘルスチェック専用ユーザ postgres postgres オンラインリカバリを実行するユーザ [server1]# psql -U postgres -p 5432 postgres=# SET password_encryption = 'scram-sha-256'; postgres=# CREATE ROLE pgpool WITH LOGIN; postgres=# CREATE ROLE repl WITH REPLICATION; postgres=# \password pgpool postgres=# \password repl postgres=# \password postgres注意: detach_false_primaryを利用する予定がある場合、"pgpool" ロールはPostgreSQLのスーパーユーザーであるか、"pg_monitor" グループに所属する必要があります。 "pgpool"ユーザをそのグループに所属させるには以下のようにします。
GRANT pg_monitor TO pgpool;
Pgpool-IIサーバとPostgreSQLバックエンドサーバが192.168.137.0/24のネットワークにあることを想定し、各ユーザがscram-sha-256認証方式で接続できるように、pg_hba.confを編集しておきます。
host all pgpool 192.168.137.0/24 scram-sha-256 host all all 0.0.0.0/0 scram-sha-256 host replication repl 192.168.137.0/24 scram-sha-256自動フェイルオーバ、オンラインリカバリ機能を利用するために3台のサーバでは、postgresユーザがパスワードなしで双方向にssh接続できる状態にする必要があります。
replユーザのパスワード入力なしで、ストリーミングレプリケーションとオンラインリカバリを行うために、すべてのサーバにてpostgresユーザのホームディレクト/var/lib/pgsql に.pgpassを作成・配置し、パーミッションを 600 に設定しておきます。
[全サーバ]# su - postgres [全サーバ]$ vi /var/lib/pgsql/.pgpass (以下を追加) server1:5432:replication:repl:<replユーザのパスワード> server2:5432:replication:repl:<replユーザのパスワード> server3:5432:replication:repl:<replユーザのパスワード> [全サーバ]$ chmod 600 /var/lib/pgsql/.pgpassPgpool-IIやPostgreSQLに接続する際には、ファイアーウォールによって目的のポートが開けられていなければなりません。CentOS/RHEL7の場合、以下のように設定します。
[全サーバ]# firewall-cmd --permanent --zone=public --add-service=postgresql [全サーバ]# firewall-cmd --permanent --zone=public --add-port=9999/tcp --add-port=9898/tcp --add-port=9000/tcp --add-port=9694/tcp [全サーバ]# firewall-cmd --permanent --zone=public --add-port=9999/udp --add-port=9898/udp --add-port=9000/udp --add-port=9694/udp [全サーバ]# firewall-cmd --reload
7.3.5. Pgpool-IIの設定
7.3.5.1. 共通設定
以下の操作はserver1, server2, server3での共通の設定です。
RPMからインストールした場合、すべてのPgpool-IIの設定ファイルは/etc/pgpool-IIにあります。今回はストリーミングレプリケーションモードのテンプレートとしてpgpool.conf.sample-streamサンプルファイルを使用します。
[全サーバ]# cp /etc/pgpool-II/pgpool.conf.sample-stream /etc/pgpool-II/pgpool.conf
Pgpool-IIが全てのIPアドレスから接続を受け付けるように、listen_addressesパラメータに'*'を設定します。
listen_addresses = '*'
レプリケーションの遅延チェックユーザsr_check_userにpgpoolユーザを設定します。 この設定例では、sr_check_passwordはpgpool.confに指定せず、pool_passwdファイルに作成します。Pgpool-II 4.0から、sr_check_passwordが空白の場合、Pgpool-IIは空のパスワードを使用する前にまずpool_passwdファイルからsr_check_userに指定したユーザのパスワードを取得できるか試みます。
sr_check_user = 'pgpool'
sr_check_password = ''
自動フェイルオーバのため、ヘルスチェックを有効にします。health_check_periodのデフォルト値が0で、これはヘルスチェックが無効であることを意味します。 また、ネットワークが不安定な場合には、バックエンドが正常であるにも関わらず、ヘルスチェックに失敗し、フェイルオーバや縮退運転が発生してしまう可能性があります。そのようなヘルスチェックの誤検知を防止するため、ヘルスチェックのリトライ回数をhealth_check_max_retries = 3 に設定しておきます。 health_check_user、health_check_passwordは前述のsr_check_user、sr_check_passwordと同様に設定します。
health_check_period = 5
# Health check period
# Disabled (0) by default
health_check_timeout = 30
# Health check timeout
# 0 means no timeout
health_check_user = 'pgpool'
health_check_password = ''
health_check_max_retries = 3
また、バックエンド情報を前述のserver1、server2及びserver3の設定に従って設定しておきます。複数バックエンドノードを定義する場合、以下のbackend_*などのパラメータ名の末尾にノードIDを表す数字を付加することで複数のバックエンドを指定することができます。
# - Backend Connection Settings -
backend_hostname0 = 'server1'
# Host name or IP address to connect to for backend 0
backend_port0 = 5432
# Port number for backend 0
backend_weight0 = 1
# Weight for backend 0 (only in load balancing mode)
backend_data_directory0 = '/var/lib/pgsql/11/data'
# Data directory for backend 0
backend_flag0 = 'ALLOW_TO_FAILOVER'
# Controls various backend behavior
# ALLOW_TO_FAILOVER or DISALLOW_TO_FAILOVER
backend_hostname1 = 'server2'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/var/lib/pgsql/11/data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_hostname2 = 'server3'
backend_port2 = 5432
backend_weight2 = 1
backend_data_directory2 = '/var/lib/pgsql/11/data'
backend_flag2 = 'ALLOW_TO_FAILOVER'
7.3.5.2. フェイルオーバの設定
PostgreSQLバックエンドノードがダウンした時に実行するスクリプトをfailover_commandに設定します。 また、PostgreSQLサーバが3台の場合、プライマリノードのフェイルオーバ後に新しいプライマリからスレーブをリカバリするためにfollow_master_commandも設定する必要があります。follow_master_commandはプライマリノードのフェイルオーバ後に実行されます。PostgreSQLサーバが2台の場合、follow_master_commandの設定は不要です。
それぞれの実行スクリプトの引数は、それぞれ実行時にPgpool-IIによってバックエンドの具体的な情報に置き換えられます。各引数の意味はfailover_commandをご参照ください。
failover_command = '/etc/pgpool-II/failover.sh %d %h %p %D %m %H %M %P %r %R'
follow_master_command = '/etc/pgpool-II/follow_master.sh %d %h %p %D %m %M %H %P %r %R'
/etc/pgpool-II/failover.sh及び/etc/pgpool-II/follow_master.shを作成し、実行権限を与えておきます。
# vi /etc/pgpool-II/failover.sh
# vi /etc/pgpool-II/follow_master.sh
# chmod +x /etc/pgpool-II/{failover.sh,follow_master.sh}
/etc/pgpool-II/failover.sh
#!/bin/bash # This script is run by failover_command. set -o xtrace exec > >(logger -i -p local1.info) 2>&1 # Special values: # %d = node id # %h = host name # %p = port number # %D = database cluster path # %m = new master node id # %H = hostname of the new master node # %M = old master node id # %P = old primary node id # %r = new master port number # %R = new master database cluster path # %% = '%' character FAILED_NODE_ID="$1" FAILED_NODE_HOST="$2" FAILED_NODE_PORT="$3" FAILED_NODE_PGDATA="$4" NEW_MASTER_NODE_ID="$5" NEW_MASTER_NODE_HOST="$6" OLD_MASTER_NODE_ID="$7" OLD_PRIMARY_NODE_ID="$8" NEW_MASTER_NODE_PORT="$9" NEW_MASTER_NODE_PGDATA="${10}" PGHOME=/usr/pgsql-11 logger -i -p local1.info failover.sh: start: failed_node_id=$FAILED_NODE_ID old_primary_node_id=$OLD_PRIMARY_NODE_ID \ failed_host=$FAILED_NODE_HOST new_master_host=$NEW_MASTER_NODE_HOST # If standby node is down, skip failover. if [ $FAILED_NODE_ID -ne $OLD_PRIMARY_NODE_ID ]; then logger -i -p local1.info failover.sh: Standby node is down. Skipping failover. exit 0 fi # Promote standby node. logger -i -p local1.info failover.sh: ssh: postgres@$NEW_MASTER_NODE_HOST pg_ctl promote if [ $UID -eq 0 ]; then su postgres -c "ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null \ postgres@$NEW_MASTER_NODE_HOST ${PGHOME}/bin/pg_ctl -D ${NEW_MASTER_NODE_PGDATA} -w promote" else ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null \ postgres@$NEW_MASTER_NODE_HOST ${PGHOME}/bin/pg_ctl -D ${NEW_MASTER_NODE_PGDATA} -w promote fi if [[ $? -ne 0 ]]; then logger -i -p local1.error failover.sh: new_master_host=$NEW_MASTER_NODE_HOST promote failed exit 1 fi logger -i -p local1.info failover.sh: end: new_master_node_id=$NEW_MASTER_NODE_ID started as the primary node exit 0
/etc/pgpool-II/follow_master.sh
#!/bin/bash # This script is run after failover_command to recover the slave from the new primary. set -o xtrace exec > >(logger -i -p local1.info) 2>&1 # special values: %d = node id # %h = host name # %p = port number # %D = database cluster path # %m = new master node id # %M = old master node id # %H = new master node host name # %P = old primary node id # %R = new master database cluster path # %r = new master port number # %% = '%' character FAILED_NODE_ID="$1" FAILED_NODE_HOST="$2" FAILED_NODE_PORT="$3" FAILED_NODE_PGDATA="$4" NEW_MASTER_NODE_ID="$5" OLD_MASTER_NODE_ID="$6" NEW_MASTER_NODE_HOST="$7" OLD_PRIMARY_NODE_ID="$8" NEW_MASTER_NODE_PORT="$9" NEW_MASTER_NODE_PGDATA="${10}" PGHOME=/usr/pgsql-11 ARCHIVEDIR=/var/lib/pgsql/archivedir REPL_USER=repl PCP_USER=pgpool PGPOOL_PATH=/usr/bin PCP_PORT=9898 # Recovery the slave from the new primary logger -i -p local1.info follow_master.sh: start: pg_basebackup for $FAILED_NODE_ID # Check the status of standby ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null \ postgres@${FAILED_NODE_HOST} ${PGHOME}/bin/pg_ctl -w -D ${FAILED_NODE_PGDATA} status >/dev/null 2>&1 # If slave is running, recover the slave from the new primary. if [[ $? -eq 0 ]]; then # Execute pg_basebackup at slave ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${FAILED_NODE_HOST} " ${PGHOME}/bin/pg_ctl -w -m f -D ${FAILED_NODE_PGDATA} stop rm -rf ${FAILED_NODE_PGDATA} ${PGHOME}/bin/pg_basebackup -h ${NEW_MASTER_NODE_HOST} -U ${REPL_USER} -p ${NEW_MASTER_NODE_PORT} -D ${FAILED_NODE_PGDATA} -X stream -R if [[ $? -ne 0 ]]; then logger -i -p local1.error follow_master.sh: end: pg_basebackup failed exit 1 fi rm -rf ${ARCHIVEDIR}/* cat >> ${FAILED_NODE_PGDATA}/recovery.conf << EOT restore_command = 'scp ${NEW_MASTER_NODE_HOST}:${ARCHIVEDIR}/%f %p' EOT $PGHOME/bin/pg_ctl -l /dev/null -w -D ${FAILED_NODE_PGDATA} start " if [[ $? -eq 0 ]]; then # Run pcp_attact_node to attach this slave to Pgpool-II. ${PGPOOL_PATH}/pcp_attach_node -w -h localhost -U ${PCP_USER} -p ${PCP_PORT} -n ${FAILED_NODE_ID} if [[ $? -ne 0 ]]; then logger -i -p local1.error follow_master.sh: end: pcp_attach_node failed exit 1 fi else logger -i -p local1.error follow_master.sh: end: follow master failed exit 1 fi else logger -i -p local1.info follow_master.sh: failed_nod_id=${FAILED_NODE_ID} is not running. skipping follow master command. exit 0 fi logger -i -p local1.info follow_master.sh: end: follow master is finished exit 0
7.3.5.3. オンラインリカバリの設定
続いて、オンラインリカバリを行うためのPostgreSQLのユーザ名およびオンラインリカバリ時に呼び出されるコマンドrecovery_1st_stageを設定します。
オンラインリカバリで実行されるpgpool_recovery関数はPostgreSQLのスーパーユーザ権限が必要なため、recovery_userにスーパーユーザを指定しなければなりません。ここでは、postrgesユーザを指定します。
オンラインリカバリ用のスクリプトrecovery_1st_stage、pgpool_remote_startをプライマリサーバ(server1)のデータベースクラスタ配下に配置し、実行権限を与えておきます。
recovery_user = 'postgres'
# Online recovery user
recovery_password = ''
# Online recovery password
recovery_1st_stage_command = 'recovery_1st_stage'
[server1]# su - postgres
[server1]$ vi /var/lib/pgsql/11/data/recovery_1st_stage
[server1]$ vi /var/lib/pgsql/11/data/pgpool_remote_start
[server1]$ chmod +x /var/lib/pgsql/11/data/{recovery_1st_stage,pgpool_remote_start}
/var/lib/pgsql/11/data/recovery_1st_stage
#!/bin/bash # This script is run by recovery_1st_stage to recovery the slave from the primary. set -o xtrace exec > >(logger -i -p local1.info) 2>&1 PRIMARY_NODE_PGDATA="$1" DEST_NODE_HOST="$2" DEST_NODE_PGDATA="$3" PRIMARY_NODE_PGPORT=$4 PRIMARY_NODE_HOST=$(hostname -s) PGHOME=/usr/pgsql-11 ARCHIVEDIR=/var/lib/pgsql/archivedir REPLUSER=repl logger -i -p local1.info online_recovery.sh: start: pg_basebackup for $DEST_NODE_HOST # Run pg_basebackup to recovery the slave from the primary ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$DEST_NODE_HOST " rm -rf $DEST_NODE_PGDATA ${PGHOME}/bin/pg_basebackup -h $PRIMARY_NODE_HOST -U $REPLUSER -p $PRIMARY_NODE_PGPORT -D $DEST_NODE_PGDATA -X stream -R " if [[ $? -ne 0 ]]; then logger -i -p local1.error online_recovery.sh: end: pg_basebackup failed. online recovery failed. exit 1 fi ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$DEST_NODE_HOST " rm -rf $ARCHIVEDIR/* cat >> $DEST_NODE_PGDATA/recovery.conf << EOT restore_command = 'scp $PRIMARY_NODE_HOST:$archivedir/%f %p' EOT " if [[ $? -ne 0 ]]; then logger -i -p local1.error online_recovery.sh: end: online recovery failed exit 1 else logger -i -p local1.info online_recovery.sh: end: online recovery is finished exit 0 fi/var/lib/pgsql/11/data/pgpool_remote_start
#!/bin/bash # This script is run to start slave node after recovery. set -o xtrace exec > >(logger -i -p local1.info) 2>&1 PGHOME=/usr/pgsql-11 DEST_HOST="$1" DEST_HOST_PGDATA="$2" logger -i -p local1.info pgpool_remote_start: start: remote start PostgreSQL@$DEST_HOST # Start slave node ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$DEST_HOST $PGHOME/bin/pg_ctl -l /dev/null -w -D $DEST_HOST_PGDATA start if [[ $? -ne 0 ]]; then logger -i -p local1.info pgpool_remote_start: $DEST_HOST start failed. exit 1 fi logger -i -p local1.info pgpool_remote_start: end: $DEST_HOST PostgreSQL started successfully.
また、オンラインリカバリ機能を使用するには、pgpool_recovery、pgpool_remote_start、pgpool_switch_xlogという関数が必要になるので、server1のtemplate1にpgpool_recoveryをインストールしておきます。
[server1]# su - postgres
[server1]$ psql template1 -c "CREATE EXTENSION pgpool_recovery"
7.3.5.4. クライアント認証の設定
事前設定の章で、Pgpool-IIとPostgreSQLの間に認証方式をscram-sha-256に設定しました。この設定例では、クライアントとPgpool-IIの間でもscram-sha-256認証方式を利用し接続するように設定します。 pgpool.confファイル内のhealth_check_password、sr_check_password、wd_lifecheck_password、recovery_passwordにはAES256暗号化形式、平文形式しか指定できないので、ご注意ください。 Pgpool-IIのクライアント認証の設定ファイルはpool_hba.confと呼ばれ、RPMパッケージからインストールする場合、デフォルトでは/etc/pgpool-II配下にインストールされます。 デフォルトではpool_hba.confによる認証は無効になっているので、pgpool.confでは以下の設定をonに変更します。
enable_pool_hba = on
pool_hba.confのフォーマットはPostgreSQLのpg_hba.confとほとんど同じです。pgpoolとpostgresユーザをscram-sha-256認証に設定します。
host all pgpool 0.0.0.0/0 scram-sha-256
host all postgres 0.0.0.0/0 scram-sha-256
Pgpool-IIのクライアント認証で用いるデフォルトのパスワードファイル名はpool_passwdです。 scram-sha-256認証を利用する場合、Pgpool-IIはそれらのパスワードを復号化するために復号鍵が必要となります。全サーバで復号鍵ファイルをrootユーザのホームディレクトリ配下に作成します。
[全サーバ]# echo '任意の文字列' > ~/.pgpoolkey
[全サーバ]# chmod 600 ~/.pgpoolkey
「pg_enc -m -k /path/to/.pgpoolkey -u ユーザ名 -p」 コマンドを実行すると、ユーザ名とAES256で暗号化したパスワードのエントリがpool_passwdに登録されます。 pool_passwd がまだ存在しなければ、pgpool.confと同じディレクトリ内に作成されます。
[全サーバ]# pg_enc -m -k /root/.pgpoolkey -u pgpool -p
db password: [pgpoolユーザのパスワード]
[全サーバ]# pg_enc -m -k /root/.pgpoolkey -u postgres -p
db password: [postgresユーザのパスワード]
# cat /etc/pgpool-II/pool_passwd
pgpool:AESheq2ZMZjynddMWk5sKP/Rw==
postgres:AESHs/pWL5rtXy2IwuzroHfqg==
7.3.5.5. Watchdogの設定
デフォルトではwatchdog機能が無効のため、server1、server2及びserver3でwatchdogを有効にします。
use_watchdog = on
アクティブ機が立ち上げる仮想IPをdelegate_IPに指定します。仮想 IP はまだ使われていないIPアドレスを指定してください。server1、server2及びserver3の共通の設定です。
delegate_IP = '192.168.137.150'
仮想IPの起動/停止、ARPリクエストの送信を行う設定パラメータif_up_cmd、if_down_cmd、arping_cmdに、ネットワーク環境に合わせてネットワークインターフェース名を設定します。 今回の例で使ったネットワークインターフェースは「enp0s8」となっています。
if_up_cmd = 'ip addr add $_IP_$/24 dev enp0s8 label enp0s8:0'
# startup delegate IP command
if_down_cmd = 'ip addr del $_IP_$/24 dev enp0s8'
# shutdown delegate IP command
arping_cmd = 'arping -U $_IP_$ -w 1 -I enp0s8'
# arping command
ipコマンドやarpingコマンドのパスがデフォルトのパスと異なる場合、環境に合わせてif_cmd_pathやarping_pathを設定しておいてください。
if_cmd_path = '/sbin'
# path to the directory where if_up/down_cmd exists
arping_path = '/usr/sbin'
# arping command path
各watchdog が稼働するサーバ情報を設定しておきます。
server1の場合
wd_hostname = 'server1' wd_port = 9000server2の場合
wd_hostname = 'server2' wd_port = 9000server3の場合
wd_hostname = 'server3' wd_port = 9000
各監視対象のPgpool-IIサーバ情報を設定しておきます。
server1の場合
# - Other pgpool Connection Settings - other_pgpool_hostname0 = 'server2' # Host name or IP address to connect to for other pgpool 0 # (change requires restart) other_pgpool_port0 = 9999 # Port number for other pgpool 0 # (change requires restart) other_wd_port0 = 9000 # Port number for other watchdog 0 # (change requires restart) other_pgpool_hostname1 = 'server3' other_pgpool_port1 = 9999 other_wd_port1 = 9000server2の場合
# - Other pgpool Connection Settings - other_pgpool_hostname0 = 'server1' # Host name or IP address to connect to for other pgpool 0 # (change requires restart) other_pgpool_port0 = 9999 # Port number for other pgpool 0 # (change requires restart) other_wd_port0 = 9000 # Port number for other watchdog 0 # (change requires restart) other_pgpool_hostname1 = 'server3' other_pgpool_port1 = 9999 other_wd_port1 = 9000server3の場合
# - Other pgpool Connection Settings - other_pgpool_hostname0 = 'server1' # Host name or IP address to connect to for other pgpool 0 # (change requires restart) other_pgpool_port0 = 9999 # Port number for other pgpool 0 # (change requires restart) other_wd_port0 = 9000 # Port number for other watchdog 0 # (change requires restart) other_pgpool_hostname1 = 'server2' other_pgpool_port1 = 9999 other_wd_port1 = 9000
ハートビート信号の送信先のホスト名とポート番号を指定します。
server1の場合
heartbeat_destination0 = 'server2' # Host name or IP address of destination 0 # for sending heartbeat signal. # (change requires restart) heartbeat_destination_port0 = 9694 # Port number of destination 0 for sending # heartbeat signal. Usually this is the # same as wd_heartbeat_port. # (change requires restart) heartbeat_device0 = '' # Name of NIC device (such like 'eth0') # used for sending/receiving heartbeat # signal to/from destination 0. # This works only when this is not empty # and pgpool has root privilege. # (change requires restart) heartbeat_destination1 = 'server3' heartbeat_destination_port1 = 9694 heartbeat_device1 = ''server2の場合
heartbeat_destination0 = 'server1' # Host name or IP address of destination 0 # for sending heartbeat signal. # (change requires restart) heartbeat_destination_port0 = 9694 # Port number of destination 0 for sending # heartbeat signal. Usually this is the # same as wd_heartbeat_port. # (change requires restart) heartbeat_device0 = '' # Name of NIC device (such like 'eth0') # used for sending/receiving heartbeat # signal to/from destination 0. # This works only when this is not empty # and pgpool has root privilege. # (change requires restart) heartbeat_destination1 = 'server3' heartbeat_destination_port1 = 9694 heartbeat_device1 = ''server3の場合
heartbeat_destination0 = 'server1' # Host name or IP address of destination 0 # for sending heartbeat signal. # (change requires restart) heartbeat_destination_port0 = 9694 # Port number of destination 0 for sending # heartbeat signal. Usually this is the # same as wd_heartbeat_port. # (change requires restart) heartbeat_device0 = '' # Name of NIC device (such like 'eth0') # used for sending/receiving heartbeat # signal to/from destination 0. # This works only when this is not empty # and pgpool has root privilege. # (change requires restart) heartbeat_destination1 = 'server2' heartbeat_destination_port1 = 9694 heartbeat_device1 = ''
7.3.5.6. /etc/sysconfig/pgpoolの設定
Pgpool-IIを起動時にpgpool_statusファイルを無視させたい場合、/etc/sysconfig/pgpoolの起動オプションOPTSに「-D」を追加します。
[全サーバ]# vi /etc/sysconfig/pgpool
(...省略...)
OPTS=" -D -n"
7.3.5.7. ログの設定
この例では、Pgpool-IIのログ出力はsyslogを利用するように設定します。
log_destination = 'syslog'
# Where to log
# Valid values are combinations of stderr,
# and syslog. Default to stderr.
syslog_facility = 'LOCAL1'
# Syslog local facility. Default to LOCAL0
全サーバではログファイルを作成します。
[全サーバ]# mkdir /var/log/pgpool-II
[全サーバ]# touch /var/log/pgpool-II/pgpool.log
次にsyslogの設定ファイルを以下のように編集します。
[全サーバ]# vi /etc/rsyslog.conf
...(省略)...
*.info;mail.none;authpriv.none;cron.none;LOCAL1.none /var/log/messages
LOCAL1.* /var/log/pgpool-II/pgpool.log
また、Pgpool-IIに関して/var/log/messagesと同様のログローテーションを行うように、logrotateの設定を以下のように行います。
[全サーバ]# vi /etc/logrotate.d/syslog
...(省略)...
/var/log/messages
/var/log/pgpool-II/pgpool.log
/var/log/secure
設定が終わったら、rsyslogサービスを再起動します。
[全サーバ]# systemctl restart rsyslog
7.3.5.8. PCPコマンドの設定
PCPコマンドを使用するにはユーザ認証が必要になるので、ユーザ名とmd5ハッシュに変換されたパスワードをpcp.confファイルに設定します。 ここではユーザ名にpgpoolを使用し、以下のコマンドを実行することで、<ユーザ名:ハッシュ化されたパスワード>が/etc/pgpool-II/pcp.confに追加されます。
[全サーバ]# echo 'pgpool:'`pg_md5 PCPコマンドパスワード` >> /etc/pgpool-II/pcp.conf
7.3.5.9. .pcppassの設定
前述のfollow_master_commandのスクリプトでパスワード入力なしでPCPコマンドを実行できるように、すべてのサーバでPgpool-IIの起動ユーザのホームディレクトリに.pcppassを作成します。
[全サーバ]# echo 'localhost:9898:pgpool:pgpool' > ~/.pcppass
[全サーバ]# chmod 600 ~/.pcppass
ここで、Pgpool-IIの設定は完了です。
7.3.6. システムの起動と停止
Pgpool-IIの設定が完了したら、次にPgpool-IIを起動します。Pgpool-IIを起動する前に、バックエンドのPostgreSQLをあらかじめ起動する必要があります。また、PostgreSQLを停止する場合、Pgpool-IIを先に停止する必要があります。
Pgpool-IIの起動
前述の事前設定の章でPgpool-IIの自動起動が設定済なので、ここでシステム全体を再起動するか、以下のコマンドを実行してください。
# systemctl start pgpool.servicePgpool-IIの停止
# systemctl stop pgpool.service
7.3.7. 動作確認
これから、動作確認を行います。まず、server1、server2、server3で以下のコマンドでPgpool-IIを起動します。
# systemctl start pgpool.service
7.3.7.1. PostgreSQL スタンバイサーバを構築
まず、Pgpool-IIのオンラインリカバリ機能を利用し、スタンバイサーバを構築します。pcp_recovery_nodeコマンドで実行されるrecovery_1st_stage_commandパラメータに指定したrecovery_1st_stageとpgpool_remote_startスプリクトが実行されるので、この 2つのスクリプトが現在稼働中のプライマリサーバserver1のデータベースクラスタの下に存在することを確認します。
# pcp_recovery_node -h 192.168.137.150 -p 9898 -U pgpool -n 1
Password:
pcp_recovery_node -- Command Successful
# pcp_recovery_node -h 192.168.137.150 -p 9898 -U pgpool -n 2
Password:
pcp_recovery_node -- Command Successful
server2とserver3のPostgreSQLがスタンバイとして起動されていることを確認します。
# psql -h 192.168.137.150 -p 9999 -U pgpool postgres -c "show pool_nodes"
ユーザ pgpool のパスワード:
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | server1 | 5432 | up | 0.333333 | primary | 0 | false | 0 | 2019-02-18 11:26:31
1 | server2 | 5432 | up | 0.333333 | standby | 0 | true | 0 | 2019-02-18 11:27:49
2 | server3 | 5432 | up | 0.333333 | standby | 0 | false | 0 | 2019-02-18 11:27:49
(3 行)
7.3.7.2. watchdogアクティブ/スタンバイの切り替え
pcp_watchdog_infoでPgpool-IIのwatchdogの情報を確認します。最初に起動したPgpool-IIが「MASTER」になります。
# pcp_watchdog_info -h 192.168.137.150 -p 9898 -U pgpool
Password:
3 YES server1:9999 Linux server1 server1
server1:9999 Linux server1 server1 9999 9000 4 MASTER #最初に起動されたサーバがMASTERになる
server2:9999 Linux server2 server2 9999 9000 7 STANDBY #スタンバイとして稼働
server3:9999 Linux server3 server3 9999 9000 7 STANDBY #スタンバイとして稼働
アクティブであるserver1のPgpool-IIを停止し、server2またはserver3がスタンバイからアクティブに昇格することを確認します。server1を停止する方法はPgpool-IIを停止する、またはマシンをシャットダウンします。ここでは、Pgpool-IIを停止します。
[server1]# systemctl stop pgpool.service
# pcp_watchdog_info -p 9898 -h 192.168.137.150 -U pgpool
Password:
3 YES server2:9999 Linux server2 server2
server2:9999 Linux server2 server2 9999 9000 4 MASTER #server2がアクティブに昇格
server1:9999 Linux server1 server1 9999 9000 10 SHUTDOWN #server1が停止された
server3:9999 Linux server3 server3 9999 9000 7 STANDBY #スタンバイとして稼働
先ほど停止したPgpool-IIを再起動し、スタンバイとして起動したことを確認します。
[server1]# systemctl start pgpool.service
[server1]# pcp_watchdog_info -p 9898 -h 192.168.137.150 -U pgpool
Password:
3 YES server2:9999 Linux server2 server2
server2:9999 Linux server2 server2 9999 9000 4 MASTER
server1:9999 Linux server1 server1 9999 9000 7 STANDBY
server3:9999 Linux server3 server3 9999 9000 7 STANDBY
7.3.7.3. 自動フェイルオーバ
psqlで仮想IPに接続し、バックエンドの情報を確認します。
# psql -h 192.168.137.150 -p 9999 -U pgpool postgres -c "show pool_nodes"
ユーザ pgpool のパスワード:
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | server1 | 5432 | up | 0.333333 | primary | 0 | false | 0 | 2019-02-18 13:08:02
1 | server2 | 5432 | up | 0.333333 | standby | 0 | false | 0 | 2019-02-18 13:21:56
2 | server3 | 5432 | up | 0.333333 | standby | 0 | true | 0 | 2019-02-18 13:21:56
(3 行)
次にプライマリであるserver1のPostgreSQLを停止し、フェイルオーバするかどうか確認してみます。
[server1]$ pg_ctl -D /var/lib/pgsql/11/data -m immediate stop
ノード1を停止後、フェイルオーバが発生し、server2がプライマリに昇格したことを確認します。
# psql -h 192.168.137.150 -p 9999 -U pgpool postgres -c "show pool_nodes"
ユーザ pgpool のパスワード:
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | server1 | 5432 | down | 0.333333 | standby | 0 | false | 0 | 2019-02-18 13:22:25
1 | server2 | 5432 | up | 0.333333 | primary | 0 | true | 0 | 2019-02-18 13:22:25
2 | server3 | 5432 | up | 0.333333 | standby | 0 | false | 0 | 2019-02-18 13:22:28
(3 行)
server3が新しいプライマリserver2のスタンバイとして起動されています。
[server3]# psql -h server3 -p 5432 -U pgpool postgres -c "select pg_is_in_recovery()"
ユーザ pgpool のパスワード:
pg_is_in_recovery
-------------------
t
(1 行)
[server2]# su - postgres
$ psql
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 行)
postgres=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 11915
usesysid | 16385
usename | repl
application_name | walreceiver
client_addr | 192.168.137.103
client_hostname |
client_port | 37834
backend_start | 2019-02-18 13:22:27.472038+09
backend_xmin |
state | streaming
sent_lsn | 0/8E000060
write_lsn | 0/8E000060
flush_lsn | 0/8E000060
replay_lsn | 0/8E000060
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
7.3.7.4. オンラインリカバリ
次に、Pgpool-IIのオンラインリカバリ機能を利用し、先ほど停止した旧プライマリサーバをスタンバイとして復旧させます。pcp_recovery_nodeコマンドで実行されるrecovery_1st_stage_commandパラメータに指定したrecovery_1st_stageとpgpool_remote_startスプリクトが現在稼働中のプライマリサーバserver2のデータベースクラスタの下に存在することを確認します。
# pcp_recovery_node -h 192.168.137.150 -p 9898 -U pgpool -n 0
Password:
pcp_recovery_node -- Command Successful
ノード1がスタンバイとして起動されたことを確認します。
# psql -h 192.168.137.150 -p 9999 -U pgpool postgres -c "show pool_nodes"
ユーザ pgpool のパスワード:
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | server1 | 5432 | up | 0.333333 | standby | 0 | false | 0 | 2019-02-18 13:27:44
1 | server2 | 5432 | up | 0.333333 | primary | 0 | false | 0 | 2019-02-18 13:22:25
2 | server3 | 5432 | up | 0.333333 | standby | 0 | true | 0 | 2019-02-18 13:22:28
(3 行)
以上で、動作確認が完了です。