5.9. フェイルオーバとフェイルバック
フェイルオーバは、Pgpool-IIから見て使用できなくなったPostgreSQLバックエンドノードをPgpool-IIが自動的に切り離す処理を指します。 これはPgpool-IIの設定に関わらず、自動的に行われるいわゆる自動フェイルオーバ処理です。 Pgpool-IIはPostgreSQLバックエンドノードが使用できなくなったことを、以下の方法で確認します。
定期的に実行されるヘルスチェック処理で確認する(詳細は項5.8を参照)。 ヘルスチェックは、Pgpool-IIからPostgreSQLバックエンドノードへ接続を試行することによってPostgreSQLバックエンドノードが正常に動いていることを確認します。 正常に接続できない場合、Pgpool-IIからPostgreSQLへのネットワーク接続のどこかがおかしいか、PostgreSQL自体が正常に動作していないか、あるいはその両方である可能性がありますが、Pgpool-IIはそれを特に区別せず、単にヘルスチェックが失敗したら、該当PostgreSQLノードが使用できないと判断します。
PostgreSQLノードへの接続の際、あるいは接続中にネットワークレベルのエラーが発生した場合。 ただし、failover_on_backend_errorがオフの場合はそのようなエラーの場合でもPgpool-IIは単にエラーをレポートしセッションが切断するのみです。
クライアントがPgpool-IIに接続済みであり、PostgreSQLにおいてシャットダウン処理が実施された場合(クライアントがまったくPgpool-IIに接続していない場合は、PostgreSQLがシャットダウンされてもフェイルオーバしないことに注意してください)。
failover_commandが設定済みでフェイルオーバが行われると、failover_commandが起動されます。 failover_commandはユーザが記述すべきもので、主な役割としては、たとえばストリーミングレプリケーションのプライマリサーバがダウンした時に、新しいプライマリサーバをスタンバイサーバの中から選択して昇格させることなどが上げられます。 そのほか、ファイルオーバが発生したことを管理者にメールで通知することなども考えられます。
フェイルオーバはこのように障害時に発生しますが、手動で意図的にフェイルオーバさせることもできます。 これをスイッチオーバと呼びます。 たとえば、スィッチオーバでPostgreSQLを意図的に切り離して、その間にバックアップを取得するなどの運用が考えられます。 スィッチオーバでは、単にPgpool-II内の状態情報をダウン状態にするだけ(ただし、failover_commandは起動される)で、PostgreSQLをダウンさせるわけではないことに注意してください。 スィッチオーバはpcp_detach_nodeコマンドで実行できます。
フェイルオーバないしスィッチオーバで切り離されたPostgreSQLノードは、自動ではもとの状態(アタッチ状態)には戻りません。 -D オプションを指定してPgpool-IIを再起動するか、pcp_attach_nodeコマンドを使用します。 その際、SHOW POOL_NODESを使って、replication_stateが"streaming"になっていることを確認することをお勧めします。 これは、スタンバイサーバがプライマリサーバとストリーミングレプリケーションで正常に接続されており、データベース内容の整合性が取れていることを示します。
5.9.1. フェイルオーバとフェイルバックの設定
- failover_command (string)
PostgreSQLバックエンドノードが切り離される時に実行するユーザコマンドを指定します。 Pgpool-IIはコマンド実行の前に、以下の特殊文字をバックエンドの具体的な情報に置き換えます。
表 5-6. フェイルオーバコマンドオプション
特殊文字 説明 %d 切り離されたノードのDBノードID %h 切り離されたノードのホスト名 %p 切り離されたノードのポート番号 %D 切り離されたノードのデータベースクラスタパス %M 古いマスターノードのID %m 新しいマスターノードのID %H 新しいマスターノードのホスト名 %P 古いプライマリノードのID %r 新しいマスターノードのポート番号 %R 新しいマスターノードのデータベースクラスタパス %N 古いプライマリノードのホスト名(Pgpool-II 4.1以降) %S 古いプライマリノードのポート番号(Pgpool-II 4.1以降) %% '%'文字 注意: マスターノードは、生きているデータベースノードの中から一番若い(小さい)ノードIDを持つノードを参照します。 ストリーミングレプリケーションモードでは、このノードはプライマリノードとは異なる場合があります。 表5-6内では、 %mはPgpool-IIによって選出された新しいマスターノードとなります。 新しいマスターノードには生きているノードで一番若い(小さい)ノードが割り当てられます。 例えば、ノード0、1、2という3つのノードを持ち、ノード1がプライマリノード、全てのノードは正常である(ダウンしているノードがない)と仮定します。 ノード1がダウンした場合、failover_command は %m = 0 で呼び出されます。 また、全てのスタンバイノードがダウンした状態でプライマリノードのフェイルオーバが起きた場合、failover_commandは %m = -1、および%H,%R,%r = "" で呼び出されます。
注意: フェイルオーバーが実行されると、基本的にPgpool-IIは子プロセスを切断します。 これにより、Pgpool-IIへの全てのアクティブセッションが終了されます。 その後、Pgpool-IIはfailover_commandを実行し、コマンドが完了した後にPgpool-IIはクライアントからの接続を再び受け付ける準備のため新しい子プロセスを起動します。
しかし、Pgpool-II 3.6以降では、そのセッションがダウンしたスタンバイを使用していない場合には、フェイルオーバが起こってもセッションが切断されません。 (ただし、フェイルオーバ処理中にそのセッションを使って問い合わせを発行すると、そのセッションは切断されるので注意してください。) プライマリサーバがダウンしたときには、依然としてすべてのセッションが切断されます。 ヘルスチェックがタイムアウトした場合にも、すべてのセッションが切断されます。 それ以外のケース、たとえばヘルスチェックの再試行回数がオーバーした場合には、全セッションの切断は起きません。
注意: スクリプトの中でpsqlやその他のコマンドを使ってバックエンドにアクセスし、情報を取り出すことはできますが、psqlを Pgpool-II自体に対して実行することはできません。 スクリプトはPgpool-IIから呼ばれ、Pgpool-IIがフェイルオーバーを実行している間に動作するからです。
failover_commandの完全な例が項8.3にあります。
このパラメータはPgpool-IIの設定を再読み込みすることで変更可能です。
- failback_command (string)
PostgreSQLバックエンドノードがPgpool-IIに復帰された時に実行するユーザコマンドを指定します。 Pgpool-IIはコマンド実行の前に、以下の特殊文字をバックエンドの具体的な情報に置き換えます。
表 5-7. フェイルバックコマンドオプション
特殊文字 説明 %d 復帰したノードのDBノードID %h 復帰したノードのホスト名 %p 復帰したノードのポート番号 %D 復帰したノードのデータベースクラスタパス %M 古いマスターノードのID %m 新しいマスターノードのID %H 新しいマスターノードのホスト名 %P 現在のプライマリノードのID %r 新しいマスターノードのポート番号 %R 新しいマスターノードのデータベースクラスタパス %N 古いプライマリノードのホスト名(Pgpool-II 4.1以降) %S 古いプライマリノードのポート番号(Pgpool-II 4.1以降) %% '%'文字 注意: スクリプトの中でpsqlやその他のコマンドを使ってバックエンドにアクセスし、情報を取り出すことはできますが、psqlを Pgpool-II自体に対して実行することはできません。 スクリプトはPgpool-IIから呼ばれ、Pgpool-IIがフェイルオーバーを実行している間に動作するからです。
このパラメータはPgpool-IIの設定を再読み込みすることで変更可能です。
- follow_master_command (string)
プライマリノードのフェイルオーバー後に実行するユーザコマンドを指定します。 スタンバイがフェイルオーバーした際にはこのコマンドは実行されません。 このコマンドは、pcp_promote_nodeコマンドによってノードを昇格する要求があった場合にも起動されます。 この機能は、マスタースレーブモードでストリーミングレプリケーション構成の場合のみ有効です。
for each backend node { if (the node is not the new primary) set down node status to shared memory status memorize that folllow master command is needed to execute } if (we need to executed follow master command) fork a child process (within the child process) for each backend node if (the node status in shared memory is down) execute follow master commandPgpool-IIはコマンド実行の前に、以下の特殊文字をバックエンドの具体的な情報に置き換えます。
表 5-8. フォローマスターコマンドオプション
特殊文字 説明 %d 切り離されたノードのDBノードID %h 切り離されたノードのホスト名 %p 切り離されたノードのポート番号 %D 切り離されたノードのデータベースクラスタパス %M 古いマスターノードのID %m 新しいプライマリノードのID %H 新しいプライマリノードのホスト名 %P 古いプライマリノードのID %r 新しいプライマリノードのポート番号 %R 新しいプライマリノードのデータベースクラスタパス %N 古いプライマリノードのホスト名(Pgpool-II 4.1以降) %S 古いプライマリノードのポート番号(Pgpool-II 4.1以降) %% '%'文字 注意: follow_master_commandが空文字列でない場合、ストリーミングレプリケーションによるマスタースレーブでプライマリノードのフェイルオーバーが完了した後に、Pgpool-IIは新しいプライマリ以外のすべてのノードを切り離し、クライアントから再び接続を受け付ける準備のため再度新しい子プロセスを起動します。 その後、Pgpool-IIは切り離されたそれぞれのノードに対してfollow_master_commandに設定したコマンドを実行します。
通常は、follow_master_commandコマンドはpcp_recovery_nodeコマンドを呼んで新しいプライマリからスレーブをリカバリするために使用します。 follow_master_command中では、pg_ctlを使ってターゲットのPostgreSQLノードが動いているかどうかを確認することをお勧めします。 たとえば、そのノードはハードウェア障害で停止しているかも知れませんし、管理者が保守のために停止しているのかも知れません。 ノードが停止している場合は、そのノードをスキップしてください。 ノードが動いている場合は、まずそのノードを停止してからリカバリしてください。 follow_master_commandの完全な例は、項8.3にあります。
このパラメータはPgpool-IIの設定を再読み込みすることで変更可能です。
- failover_on_backend_error (boolean)
onに設定した場合、Pgpool-IIはPostgreSQLバックエンド接続からの読み出し、書き込みのエラーをバックエンドノードの故障と見なし、現在のセッションを切断した後にそのノードをフェイルオーバします。 offに設定した場合、そのようなエラーの場合でもPgpool-IIは単にエラーをレポートしセッションが切断するのみです。
注意: failover_on_backend_errorをoffにする場合は、バックエンドのヘルスチェックを有効にすることをお勧めします(項5.8をご覧ください)。 なお、PostgreSQLバックエンドサーバが管理コマンドでシャットダウンされたことをPgpool-IIが検知した場合には、依然としてフェイルオーバが起こることに注意してください。 この場合にもフェイルオーバを避けたい場合には、backend_flagでDISALLOW_TO_FAILOVERを指定してください。
このパラメータはPgpool-IIの設定を再読み込みすることで変更可能です。
注意: Pgpool-II V4.0より前では、この設定パラメータの名前はfail_over_on_backend_errorでした。
- search_primary_node_timeout (integer)
フェイルオーバが起きた時にプライマリノードを検索するための最大時間を秒単位で指定します。 Pgpool-IIは、ここで設定した時間の間にプライマリノードを見つけられなかった場合、探すのを諦めます。 デフォルト値は300です。 0を指定すると、永久に検索し続けます。
このパラメータはストリーミングレプリケーションによるマスタースレーブモードの場合のみ有効です。
このパラメータはPgpool-IIの設定を再読み込みすることで変更可能です。
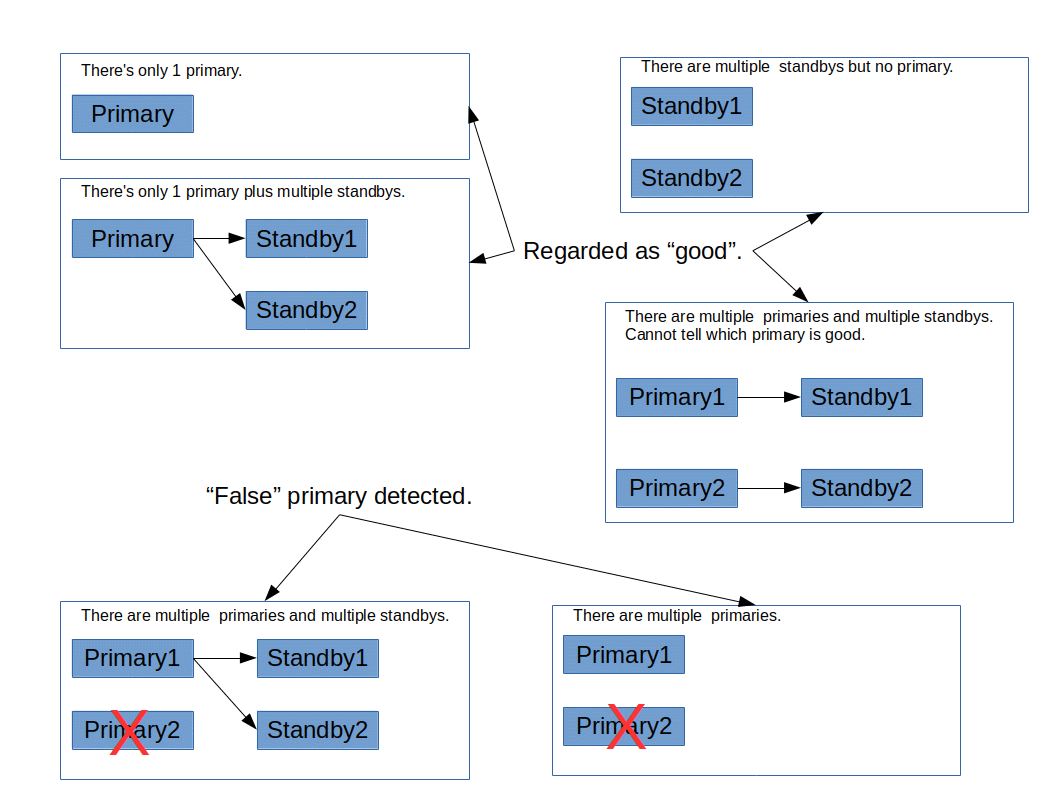
- detach_false_primary (boolean)
onにすると、不正なプライマリを切り離します。 デフォルトはoffです。 このパラメータは、ストリーミングレプリケーションモードでかつ、PostgreSQL 9.6以降を使っている場合にのみ有効です。 というのも、
pg_stat_wal_receiverを使っているからです。 PostgreSQL 9.5以前を使っている場合は、エラーは報告されず、単にこの設定は無視されます。プライマリノードが存在しない場合は、検査を実施しません。
スタンバイノードが存在せず、プライマリノードがひとつだけ存在する場合は検査を実施しません。
スタンバイノードが存在せず、プライマリノードが複数存在する場合は、もっとも若いノード番号を持つプライマリノードだけを残し、それ以外は切り離します。
もし複数のプライマリと一つ以上のスタンバイがある場合は、PostgreSQL 9.6以降であれば、プライマリとスタンバイノードの間の接続性を
pg_stat_wal_receiverで検証します。 もしあるプライマリがすべてのスタンバイに接続している場合は、そのプライマリは「正しい」と見なされ、それ以外のプライマリは「不正」と見なされ、detach_false_primaryがonなら不正なプライマリは切り離されます。 もし、正しいプライマリが見つからない場合は、何も起きません。Pgpool-IIが起動した時、不正なプライマリのチェックはPgpool-IIのメインプロセスの中で一度だけ行われます。 もしsr_check_periodが0より大きければ、不正なプライマリのチェックは、ストリーミングレプリケーションの遅延チェックと同じタイミングで行われます。
注意: この機能を使うためには、sr_check_userはPostgreSQLのスーパーユーザーであるか、"pg_monitor"グループに所属していなければなりません。 sr_check_userをpg_monitorグループに所属させるには、以下のSQLコマンドをPostgreSQLスーパーユーザーで実行してください("sr_check_user"をsr_check_userの設定値で置き換えてください)
GRANT pg_monitor TO sr_check_user;
PostgreSQL 9.6にはpg_monitorグループがないので、sr_check_userはPostgreSQLのスーパーユーザーでなければなりません。
このパラメータは、ストリーミングレプリケーションモードの時だけに適用されます。
このパラメータはPgpool-IIの設定を再読み込みすることで変更可能です。
- auto_failback (boolean)
onに設定した場合、ストリーミングレプリケーションが正常に動作しており、かつバックエンドノードのステータスがダウンのとき、スタンバイノードを自動で復帰させることができます。 これは、一時的なネットワーク障害などによりスタンバイノードが認識できず縮退が行われた場合などに役立ちます。
この機能を使用するためには、項5.11が有効であり、バックエンドノードとしてPostgreSQLが9.6以降である必要があります。 プライマリノードの
pg_stat_replicationを使用しており、自動フェイルバックはスタンバイノードに対してのみ実行されます。 メンテナンスなどで、一時的にスタンバイノードを切り離す場合は、このパラメータをOFFにしてから実施してください。 意図せずスタンバイノードが復帰してしまう可能性があります。デフォルトはoffです。 このパラメータはPgpool-IIの設定を再読み込みすることで変更可能です。
- auto_failback_interval (integer)
自動フェイルバックの実行間隔の最小時間を秒単位で指定します。 次の自動フェイルバックは前回の自動フェイルバックから指定した時間経過するまで実行されません。 ネットワークのエラーなどによりPgpool-IIが頻繁にバックエンドのDOWNを検出するような場合、大きい値を設定することでフェイルバックとフェイルオーバが繰り返される事を防ぐことができます。 デフォルトは60です。 0を指定すると自動フェイルバックは待ちません。 このパラメータはPgpool-IIの設定を再読み込みすることで変更可能です。
5.9.2. rawモードにおけるフェイルオーバ
rawモードにおいて、複数のバックエンドサーバが定義されている場合、フェイルオーバが可能です。 通常の動作ではPgpool-IIはbackend_hostname0で指定したバックエンドにアクセスします。 何らかの理由でbackend_hostname0のサーバに障害が発生すると、Pgpool-IIはbackend_hostname1へのアクセスを試みます。 これが失敗した場合にはPgpool-IIはbackend_hostname2, 3と以下同様に試みます。